概览
容器,就是可以容纳其它对象的对象,从 JDK 1.2 开始,Java 提供了 Java Collection Framework(JCF) 给开发者提供了一个通用的容器框架。
容器中只能放对象,对于基本类型(int、long、float 等)需要包装成对应的对象(Integer、Long、Float)才能放入容器。大多数时候装箱和拆箱都是自动完成的,这会造成一定程度上的性能和空间开销,但是简化了设计和编码,提高了开发效率。使用容器大概有如下优点:
- 降低学习难度
- 降低编程难度
- 降低设计和实现相关 API 的难度
- 提高程序可复用性
- 提高 API 之间的互操作性
- 提高程序性能(容器的底层数据结构和算法通常过了大规模的功能和性能验证,大部分场景下性能会比我们自己写的好)
Java 集合框架分为 Collection 和 Map 两大类,Collection 是存储单元素的容器,Map 是存储键值对(两个对象)的容器。
详情的 JCF 类图如下,包含并发和非并发实现,以及底层数据结构:

在 J.U.C(java.util.concurrent) 提供并发容器之前,所有容器都在 java.util 包下,其中大部分都是非线程安全的,这意味着多个线程并发读写时可能会出现数据不一致的情况。
即使提供了线程安全的实现,也是比较简单粗暴的使用 Synchronized 关键字对操作加锁,比如线程安全的 Map 容器:HashTable,和线程安全的 Collection 容器:Vector,实际上这些容器在并发读写的需求下,只能保证安全,不能保证高效,因此基本都已经不推荐使用了。
非并发集合
我们先来看一下实际开发中使用得最多的 “单线程容器”,其类图结构大概如下图:
Collection
Collection 接口是 JDK 中所有单元素容器的祖先接口,其下主要有三个接口,分别是可重复集合容器接口 List,不可重复集合容器接口 Set,和队列容器接口 Queue,分别适用于不同场景。
List
List 是一个元素有序、可重复、可为空的集合接口,集合中每个元素都有对应的顺序索引,默认按照元素的添加顺序设置下标,可以通过下标访问指定位置的元素,但是由于不同实现类中底层使用的数据结构不同,添加、删除和随机访问的时间复杂度各不相同。
ArrayList
ArrayList 是基于数组实现的容器类,每个 ArrayList 都有一个容量(capacity)表示底层数组的大小,当容量不足时,ArrayList 会自动扩容,默认扩容步长是当前容量的 1.5 倍。
由于 ArrayList 的底层数据结构是数组,需要连续的内存空间,所以自动扩容实际上是申请一个原来大小 1.5 倍的新数组,然后将原数组中的数据拷贝到新数组中,这个操作是比较耗时的。
因此在使用 ArrayList 时,可以使用如下两个技巧,尽量避免或减少扩容操作,提高效率:
- 在初始化时,尽量设置一个合理的初始大小,减少扩容频率。
- 在添加大量元素之前,可以手动调用
ensureCapacity(int minCapacity)增大容量,减少递增式扩容的次数。
基于数组的数据结构,ArrayList 随机访问的的效率非常高,时间复杂度是 O(1),而插入和删除的效率稍低,时间复杂度是 O(n)
ArrayList 详细的源码解析参考这里
LinkedList
LinkedList 是基于链表实现的容器类,同时实现了 List 接口和 Queue 接口的集合,这意味它既可以当做顺序容器(List)使用,又可以当做队列(Queue)使用,还可以当做栈(Stack)来使用。
实际上,当我们需要栈或者队列时,应该首选 ArrayDeque,在栈和队列的使用场景中,ArrayDeque 比 LinkedList 性能更好。所以 LinkedList 更多的时候还是用来当做顺序集合(List)来使用。
基于链表的数据结构,LinkedList 插入和删除的效率非常高,时间复杂度是 O(1),而随机访问的效率稍低,时间复杂度是 O(n),而且不存在扩容时的数据拷贝导致的效率问题。
LinkedList 详细的源码解析,参考这里
Vector
Vector 基本和 ArrayList 基本一样,但是内部使用 synchronized 对所有读写操作都做了同步,因此是线程安全的,但是应为 synchronized 本身实现线程安全的方式效率并不高,所以在多线程高并发场景下,使用 Vector 可能会造成性能问题,应该使用 JUC 中提供的 CopyOnWriteArrayList。
Stack
Stack 继承自 Vector,是一个使用数组实现的栈结构,由于功能和性能限制,现在已经不推荐使用了,如果需要栈结构,应该使用 Queue 接口下的 ArrayDeque 实现类,参考下文 ArrayDeque 的介绍。
Set
Set 接口中的方法基本和 List 一样,区别在于 Set 集合中不允许重复元素,如果添加相同的元素到 Set 集合中,第二次添加时 add() 方法会返回 false,数据会添加失败,Set 接口也不强制保证集合中元素的顺序,不同的实现类根据自身的实现方式决定是否保持顺序,并且也不限制元素是否可为空,不同的实现类可否为空的特点不同。
Set 接口的实现其实就是把对应的 Map 接口的实现进行一层包装,比如 HashSet 是对 HashMap 的包装,TreeSet 是对 TreeMap 的包装,LinkedHashSet 是对 LinkedHashMap 的包装。
HashSet
HashSet 实际上是对 HashMap 的一个包装,如下代码所示:
public class HashSet<E> {
......
//HashSet里面有一个HashMap
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {
//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
所以其实现原理和 HashMap 一致,参考下文 HashMap 的实现与特点。
TreeSet
TreeSet 实际上也是对 TreeMap 的一个包装,如下代码:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>,
Cloneable, java.io.Serializable {
......
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet() {
// TreeSet里面有一个TreeMap
this.m = new TreeMap<E,Object>();
}
......
public boolean add(E e) {
//简单的方法转换
return m.put(e, PRESENT)==null;
}
......
}
所以其实现原理和 TreeMap 一致,参考下文 TreeMap 的实现与特点。
LinkedHashSet
LinkedHashSet 实际上也是对 LinkedHashMap 的包装,基本就是这样:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
//简单的方法转换
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
......
}
所以其实现原理和 LinkedHashMap 一致,参考下文 LinkedHashMap 的实现与特点。
Queue
Queue 是 JDK 中队列也继承自 Collection 接口,除了 Collection 接口中的方法,还额外提供了两组共 6 个方法,规范队列特征的能力,一组是抛出异常的实现,一组是返回值的实现(没有则返回 null)
| hrows exception | Returns special value | |
|---|---|---|
| Insert | add(e) | offer(e) |
| Remove | remove(e) | poll(e) |
| Examine | element(e) | peek(e) |
Deque & ArrayDeque
Deque 是(double ended queue)的简称,顾名思义就是双端队列,是继承自 Queue 接口的子接口。
我们知道,在数据结构中,队列(Queue)和栈(Stack)的是很相似的,队列的出入口分别在两端,所以是先进先出(FIFO),而栈的出入口在同一端,所以是后进先出(LIFO)。而双端队列的两端分别都可以做出入口,如果封住其中的一端,那就变成了栈,所以双端队列也可以直接当做栈来用。
当做队列使用时,下表列出了 Deque 与 Queue 相对应的接口:
| Queue Method | Equivalent Deque Method | 说明 |
|---|---|---|
add(e) |
addLast(e) |
向队尾插入元素,失败则抛出异常 |
offer(e) |
offerLast(e) |
向队尾插入元素,失败则返回 false |
remove() |
removeFirst() |
获取并删除队首元素,失败则抛出异常 |
poll() |
pollFirst() |
获取并删除队首元素,失败则返回 null |
element() |
getFirst() |
获取但不删除队首元素,失败则抛出异常 |
peek() |
peekFirst() |
获取但不删除队首元素,失败则返回 null |
当做栈使用时,下表列出了 Deque 和 与 Stack(已退休的栈结构实现)对应的接口:
| Stack Method | Equivalent Deque Method | 说明 |
|---|---|---|
push(e) |
addFirst(e) |
向栈顶插入元素,失败则抛出异常 |
| 无 | offerFirst(e) |
向栈顶插入元素,失败则返回 false |
pop() |
removeFirst() |
获取并删除栈顶元素,失败则抛出异常 |
| 无 | pollFirst() |
获取并删除栈顶元素,失败则返回 null |
peek() |
peekFirst() |
获取但不删除栈顶元素,失败则抛出异常 |
| 无 | peekFirst() |
获取但不删除栈顶元素,失败则返回 null |
上面两个表共定义了 Deque 的 12 个接口。添加,删除,取值都有两套接口,它们功能相同,区别是对失败情况的处理不同。一套接口遇到失败就会抛出异常,另一套遇到失败会返回特殊值(false 或 null)。除非某种实现对容量有限制,大多数情况下,添加操作是不会失败的。虽然 Deque 的接口有12个之多,但无非就是对容器的两端进行操作,或添加,或删除,或查看。掌握这个规律,其实理解起来就不难了。
Deque 接口有两个实现类:ArrayDeque 和 ArrayList,这两个实现既可以当做队列使用,也可以当做栈使用。但是实际上,在队列和栈的场景中,ArrayDeque 的性能是要优于 ArrayList 的,所以在这些场景下,我们还是优先使用 ArrayDeque 比较好。
PS:我个人没看出来 ArrayList 实现 Deque 接口的作用,可能是历史原因吧。
从名字上就能看得出来,ArrayDeque 是通过数组实现的,更具体来讲是循环数组,也就是说该数组上任何一点都能看作起点或者终点。
同样,ArrayDeque 也是非线程安全的,如果需要并发安全且高效的队列,还是应该去 J.U.C 中去找对应的实现。另外,ArrayDeque 中不允许放入 null
元素。
ArrayDeque 详细的源码解析,参考这里
PriorityQueue
PriorityQueue 是 Queue 接口中一个比较特殊的实现,顾名思义就是优先队列,其作用是能够保证每次取出的元素都是队列中权重值最小的,这里牵涉到了容器中元素中的大小关系,那么就需要比较,其大小判断可以通过元素本身的自然顺序(nature ordering),也可以通过构造时传入的比较器(Comparator),这个设计和 TreeMap 是一致的。
PriorityQueue 中不允许放入 null 元素,其通过堆(BinaryHeap) 实现,或者说是通过完全二叉树(Complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值)。实际上数组也可以用来作为实现 PriorityQueue 的底层数据结构。
PriorityQueue 的 peek()、element() 操作时间复杂度都是 O(1),而 add()、 offer() 和无参数的 remove() 以及 poll() 方法的时间复杂度都是 O(log\ n),总的来说,效率还是非常高的。
PriorityQueue 详细的源码解析,参考这里
Map
Map 接口可以看作是和 Collection 平级的借口,是 JDK 中所有键值对容器的祖先接口,按照是否保持容器中元素的顺序,大概可以分为两类:
- 实现了 SortedMap 接口的“有序 Map”,以及一个特殊的 EnumMap
- 没有实现 SortedMap 接口的 “无序 Map”
HashMap
HashMap 是 Map 接口最重要的实现类之一,也是日常 Java 开发中最常用的键值对数据结构之一。可以放入 key 为 null 的元素,也可以放入 value 为 null 的元素。
HashMap 是基于 散列表(Hash Table) 数据结构的容器,但是散列表必须要解决散列冲突的问题,散列冲突目前主要有两种解决方案:开放寻址法(open addressing)和链表法(chaining),HashMap 使用链表法解决散列冲突问题。
理论上 HashMap 的读、写、删除的效率都是 O(1),非常高效,但是由于散列冲突问题的存在,HashMap 实际性能表现可能不太稳定,而且不一定能达到理论效率。
影响 HashMap 性能的两个最重要的参数是:初始容量(initial capacity)和负载系数(load factory)
初始容量指定了初始 table 的大小,复杂系数指定了 bucket 自动扩容的临界值。当 entry 的个数超过 capacity * load_factory 时,容器将自动扩容并重新散列。对于插入元素较多的 HashMap,将初始容量设置得大一些可以减少自动扩容(同 ArrayList 的原理)和重新散列的次数。
为了优化 HashMap 的实际性能,其具体实现在 JDK 8 前后有一些差别。
HashMap 详细的源码解析,参考这里
Before JDK 8
在 JDK 8 之前,HashMap 底层用数据结构是数组+链表,用数组做 buckets,实际数据存储在每个 bucket 后的链表中,其大致结构如下:
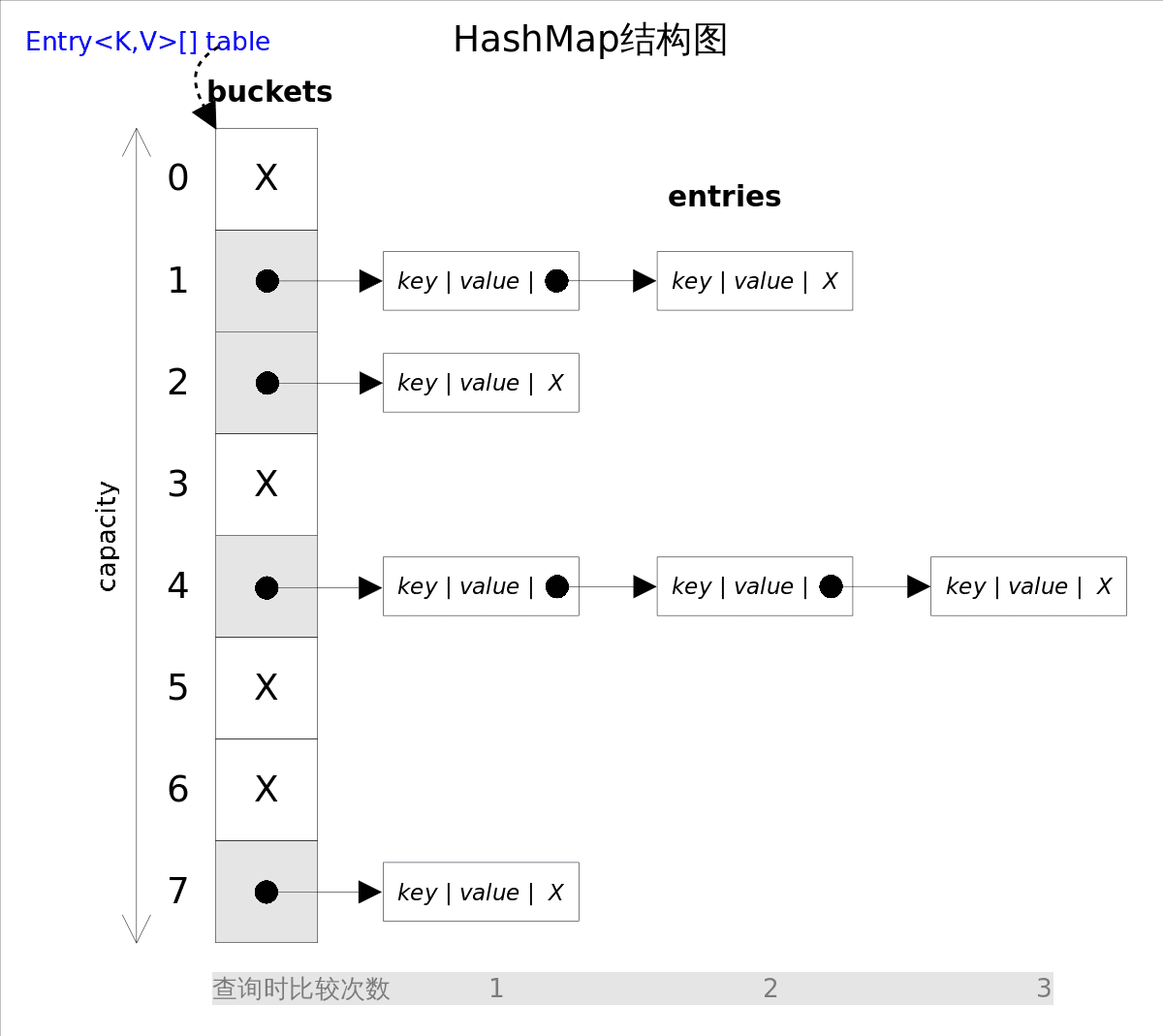
这是非常经典的散列冲突解决方案,但是在数据量很大或者散列不够均匀的时候,容易导致数据节点链表过长,会降低散列表的读取性能,达不到理想状态下的 O(1) 时间复杂度,甚至是达到 O(n) 级别。
After JDK 8
在 JDK 8(含)之后,HashMap 最大的变化就在底层数据结构上引入了红黑树,为了降低数据节点的查询开销,在节点数据达到 8 个的时候,会将链表转为红黑树,这样在节点数据比较多的时候,时间复杂度可以降到 O(log_n)
其结构示意图如下:

红黑树是一个性能非常稳定的近似平衡二叉查找树(binary seach tree)结构,当一个节点的数据确实比较多(可能是因为散列函数设计得不好,也可能是数据量实在太大)的时候,转成红黑树结构是一个非常靠谱的提升 HashMap 整体性能的方法。
虽然红黑树实现起来比链表复杂的多,但是好在 JDK 的工程师们已经帮我们最好了这部分的工作,我们只需要升级到 JDK 8,就可以不改一处代码,享受 HashMap 的性能提升。
HashTable
HashTable 基本和 HashMap 差不多,只是内部各个方法用 Synchronized 实现了同步,在多线程读写的情况下,不会出现数据不一致。
但是 HashTable 多线程读写的性能并不好,所以,如果确实需要多线程读写安全的 Map 容器,应该使用 J.U.C 提供的 ConcurrentMap 接口的实现类,比如 ConcurrentHashMap,而不应该使用 HashTable,HashTable 该退休了。
LinkedHashMap
LinkedHashMap 是 HashMap 的直接子类,所以 key 和 value 同样可以为空。看这个名字大概就能猜到,这是 LinkedList 和 HashMap 的结合,可以将 LinkedHashMap 看作是用 LinkedList 强化过的 HashMap。如下是 LinkedHashMap 的结构图:

从图上能看出来,LinkedHashMap 和 HashMap 主体结构上完全一致,区别在于 LinkedHashMap 使用双向链表实现了冲突链表,并且这个双向链表将所有的 entry 都连了起来,这样做相比 HashMap 有两个额外的好处:
- 可以保证元素的迭代顺序和插入顺序相同。
- 迭代整个 Map 的时候,不需要像 HashMap 那样迭代整个 table,而是只需要遍历 header 指向的双向链表即可,也就是 LinkedHashMap 的迭代时间和 Table 的大小无关,而是只与实际上 entry 的数量有关。
由于主体结构和 HashMap 一样,所以影响 LinkedHashMap 性能的也是初始容量(initial capacity)和负载系数,原因也和 HashMap 一样。
LinkedHashMap 除了保证迭代顺序之外,还有一个非常有用的用法:轻松实现一个先进先出(FIFO)策略的缓存结构,注意,是缓存,不是队列。
LinkedHashMap 有一个 HashMap 中没有的子类方法:boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉 Map 是否要删除“最老”的 Entry,所谓最老就是当前 Map 中最早插入的 Entry,如果该方法返回 true,最老的那个元素就会被删除。而且在每次插入新元素的之后LinkedHashMap 会自动询问 removeEldestEntry() 是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让 removeEldestEntry() 返回 true,就能够实现一个固定大小的FIFO策略的缓存。示例代码如下:
/** 一个固定大小的 FIFO 替换策略的缓存 */
class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当 Entry 个数超过 cacheSize 时,删除最老的 Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}
LinkedHashMap 更加详细的源码解析,参考 这里
TreeMap
TreeMap 实现了 SortedMap 接口,意味着容器内部会按照 key 的大小对 Map 中的元素进行排序,而 key 大小的判断,既可以通过其自身的自然顺序(natural ordering),也可以通过构造时传入的比较器 Comparator。
TreeMap 底层使用红黑树(Red-Black Tree)实现,这意味着其读取、插入和删除的时间复杂度都是 O(log_n),而且得益于红黑树独特的结构,TreeMap 的性能稳定性也很好。其结构大致如下图:
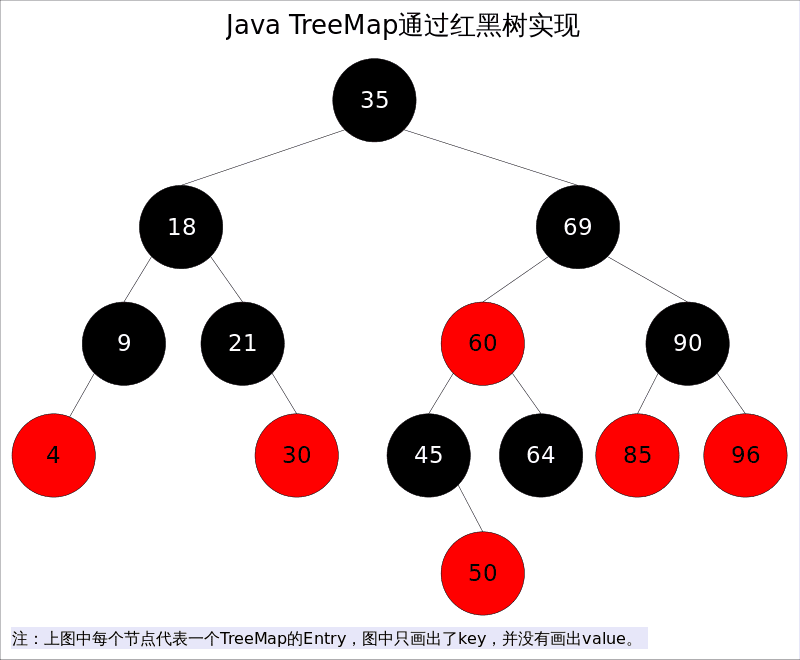
出于性能原因,TreeMap 是非同步的,这意味着它不能在多线程读写情况下使用,如果需要“多线程安全的 TreeMap”,可以用 Collections.synchronizedSortedMap 做如下包装:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
同样还是由于 Synchronized 本身性能开销较大,不建议使用这种方式。所以,如果有这样的需求,可以直接使用 J.U.C 包中提供的 ConcurrentSkipListMap 实现。
如上 HashMap 中所述,红黑树本身的实现和操作比较复杂,涉及到各种左旋右旋和颜色调整,详细源码分析参考这里
EnumMap
EnumMap 是一个有点特别的 Map 接口实现类,他是一个针对枚举(enum)类型 key 优化过的 Map,在要存储的键值对所有的 key 都是 enum 类型的时候,使用 EnumMap 会比 HashMap 更高效。
我们知道 HashMap 是通过散列函数计算 key 的值,然后储存到数组中,这个过程中就会产生两个可能会影响性能的点:散列函数性能和散列冲突的解决。
如果我们要存储的数据的 key 都是 enum 类型的话,编译器会为每个枚举类型生成的常量序列号,也就是 ordinal,这个值是不会冲突的,那么就只需要将这个值设置为数组的下标就可以了,这样一来就可以直接避免使用散列函数,就可以大幅提高读写性能,读、写、删除的时间复杂度都是 O(1)
所以,如果要存储到 Map 中的的数据 key 都是 enum 类型,建议使用 EnumMap 代替 HashMap,可以有效提高综合性能。
WeakHashMap
如果说 EnumMap 是个有点特别的 Map,那么 WeekHashMap 就是十分特别的 Map。它的特别之处在于 WeekHashMap 中的元素(entry)可能随时被 GC 自动删除,即便我们没有手动的调用 remove() 或者 clear() 函数。
更直观的来说,即便我们没有显示的删除其中的元素,也有可能随时发生如下的情况:
- 调用两次
size()方法返回不同的值; - 两次调用
isEmpty()方法,第一次返回false,第二次返回true; - 两次调用
containsKey()方法,第一次返回true,第二次返回false,尽管两次使用的是同一个key; - 两次调用
get()方法,第一次返回一个value,第二次返回null,尽管两次使用的是同一个对象。
程序员最怕的就是不可控,而这个 WeekHashMap 似乎非常疯狂,简直不知道把数据存进去之后会发生什么!
其实这个特点非常适合一种场景:缓存。
在缓存的场景下,可控缓存使用的内存是有限的,不可能缓存所有数据;缓存命中了可以提高系统效率;但是不命中也不会造成错误,所以 WeekHashMap 其实是一个天然的最少使用策略 LUF(Least Frequently Used)的缓存容器。
要明白 WeekHashMap 的工作原理,先要了解弱引用这个概念。
我们知道 Java 程序中的内存是通过 GC 自动管理的,GC 在程序运行的过程中会通过一系列非常复杂的机制自动判断哪些对象需要被回收,并释放对应的内存空间。而 GC 判断某个对象是否应该被回收的一个依据是:是否有有效的引用指向该对象,因为 Java 中是通过引用访问所有对象的,如果一个对象没有对应某个有效的引用,那么这个对象就无法被使用,那么就应该被回收。这里的有效引用不包括弱引用。
也就是说,弱引用确实可以用来访问对象,但是仅有弱引用指向的对象在垃圾回收时并不会被 GC 考虑在内。好比说,你把东西放在小区的垃圾桶里,你确实可以在垃圾桶里找到你放进去的东西,但是垃圾车来收垃圾的时候,并不会考虑你放在垃圾桶里的东西,他会连同垃圾一并收走。
WeekHashMap 内部就是通过弱引用来管理 entry 的,这意味着将一对 key-value 对象放进 WeekHashMap 之后,他就有可能随时被 GC 回收,除非该对象在 WeekHashMap 之外还有强引用。
关于强引用、弱引用以及其他的 Java 引用类型,可以参考 这里
除了这个特殊的管理 entry 的方式,其他方面 WeekHashMap 和 HashMap 没有什么大的区别,其具体实现可以参考前文的 HashMap。
并发集合
J.U.C 包的出现给 Java 并发编程效率带来了巨大的提升,其中就提供了不少在并发情况下既保证数据安全,又保证效率的集合,让古老的 Vector 和 HashTable 直接退休!
容我先学学再来更新 :)
评论